Chapter 1
Introduction: The Dictionary Problem
J
ack and Jill have a problem. They are writing a software program for playing Scrabble and they need a dictionary to look up words. The most natural way to do this is to read in a file of words when the program first starts up. Depending on the size of the dictionary, this file could become quite lengthy, perhaps 50,000 words. Jack's job is to gather the words into a file named words.txt, with one word per line. He starts out with just seven words, planning to add the other 49,993 words tomorrow or the next day (Example 1-1).
Example 1-1. words.txt File
hill
fetch
pail
water
up
down
crown
|
Meanwhile, Jill starts coding the Java dictionary object. She uses a very straightforward approach. When the
Dictionary0 object is created, it will read in the words from the file words.txt and store them in the Vector called "words." A Vector is a variable-length list of items (Example 1-2).
Example 1-2: Dictionary0.java
import java.io.*;
import java.util.*;
class Dictionary0 {
Vector words = new Vector();
Dictionary0() {
loadWords();
}
void loadWords() {
try {
BufferedReader f = new BufferedReader(
new FileReader("words.txt"));
String word = null;
while ((word = f.readLine())!=null) {
words.addElement(word);
}
} catch (Exception e) {
System.err.println("Unable to read from words.txt");
// continue with empty dictionary
}
}
public boolean isWord(String w) {
for (int j=0; j<words.size(); ++j) {
String w2 = (String) words.elementAt(j);
if (w.equals(w2)) {
return true;
}
}
return false;
}
}
|
Jill only needs the method
isWord to determine whether a word is in the dictionary, which is good enough for her Scrabble game. But she is starting to think that this dictionary object might also be useful in other game programs she would like to write some day. Jill is also thinking that Vector might not be the best way to store the words, and a linear search might not be the best thing to do now, but as a good engineer she knows that she must first get it right, and later she can make it fast. And indeed, she tests the program and everything runs smoothly and fast!
The next day, Jack finishes his job of adding the other 49,993 words to the dictionary, and Jill discovers a major problem when she runs the program. As expected, the linear search is just a bit too slow, but since words are not looked up very often in Scrabble, it isn’t too bad. The real problem is that it takes too long to start up the program, because reading in a file with 50,000 words is just too costly.
Jill sighs, but then remembers that the Scrabble game will be distributed as an applet on the Web, and later it will be installed on a Java hand-held game machine, and in neither case will she be able to easily read in the words from a file anyway. So, Jill writes a much simpler and faster program where the words are stored in an initialized array instead of read from a file (Example 1-3).
Example 1-3: Dictionary1.java
class Dictionary1 {
String[] words = {
"hill",
"fetch",
"pail",
"water",
"up",
"down",
"crown"
};
boolean isWord(String w) {
for (int j=0; j<words.length; ++j) {
if (w.equals(words[j])) {
return true;
}
}
return false;
}
}
|
The dictionary is part of this program, and the words do not need to be read in when the program starts. Again, she runs and tests her new program and is satisfied with the results.
Like any good software engineer, Jill ponders the difference between her two programs (Figure 1-1):
- Performance
: The two programs differ in speed. In
Dictionary0 the words must be read from a file and stored in a data structure. This computation is performed every time the program is executed. In Dictionary1 this work is done at compile time. The resulting executable is larger and therefore may take more time to load, but in general it is much faster than the first approach (and it will be lightning fast for the Java hand-held game machine). Also, compiler optimizations may provide another performance boost. The words array could be declared final and the compiler could use this information to create faster and shorter code.
Simplicity: Simplicity is in the eye of the beholder. At first glance it would appear that Dictionary1 is simpler, because we don't need the initialization code or the loadWords method. What will Jack think?
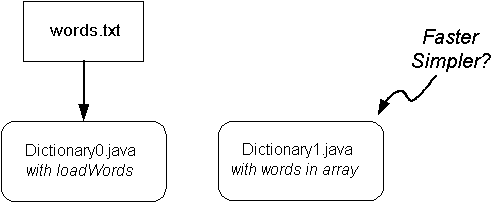
Figure 1-1: Dictionary0 and Dictionary1
When Jack gets wind of Jill's changes, he is upset. He has just spent the whole day typing in 49,993 words into the words.txt file. What will Jack do? He certainly won't want to type them in again with quotes and commas. Besides, he likes his simple file a lot better than one cluttered with quotes and commas. Then he gets an idea: just write a program to read the words in the file words.txt, slap on some quotes and a comma, and output the array data for the
Dictionary1 program (Figures 1-2 and 1-3). He can reuse the loadWords method from Dictionary0 and just execute the lines:
for (int j=0; j<words.size(); ++j) {
System.out.println(" \""+words.elementAt(j)+"\",");
}
Jack likes this because he can continue using words.txt, and the translation program will create the file that Jill can use for her program. Jill also thinks it’s a cool idea, but she doesn't look forward to cutting and pasting the words into her program. So she suggests that, instead of generating a 50,000-line file, why not just generate the whole program, all 50,014 lines? It's only 14 lines longer. And there you have it—the birth of a program generator (Example 1-4).
Example 1-4: Dictionary1Generator.java
import java.io.*;
import java.util.*;
class Dictionary1Generator {
static Vector words = new Vector();
static void loadWords() {
try {
BufferedReader f =
new BufferedReader(new FileReader("words.txt"));
String word = null;
while ((word = f.readLine())!=null) {
words.addElement(word);
}
} catch (Exception e) {
System.err.println("Unable to read words from words.txt");
// continue with empty dictionary
}
}
static public void main(String[] args) {
loadWords();
// Generate Dictionary1 program
System.out.println("class Dictionary1 {\n");
System.out.println(" String words = {");
for (int j=0; j<words.size(); ++j) {
System.out.println(" \""+words.elementAt(j)+"\",");
}
System.out.println(" };");
System.out.println("\n");
System.out.println(" public boolean isWord(String w) {");
System.out.println(" for (int j=0; j<words.length; ++j) {");
System.out.println(" if (w.equals(words[j])) {");
System.out.println(" return true;");
System.out.println(" }");
System.out.println(" }");
System.out.println(" return false;");
System.out.println(" }");
System.out.println("}");
}
}
|
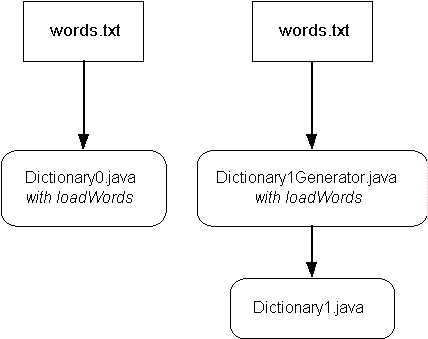
Figure 1-2: The Dictionary1Generator creates Dictionary1.java.
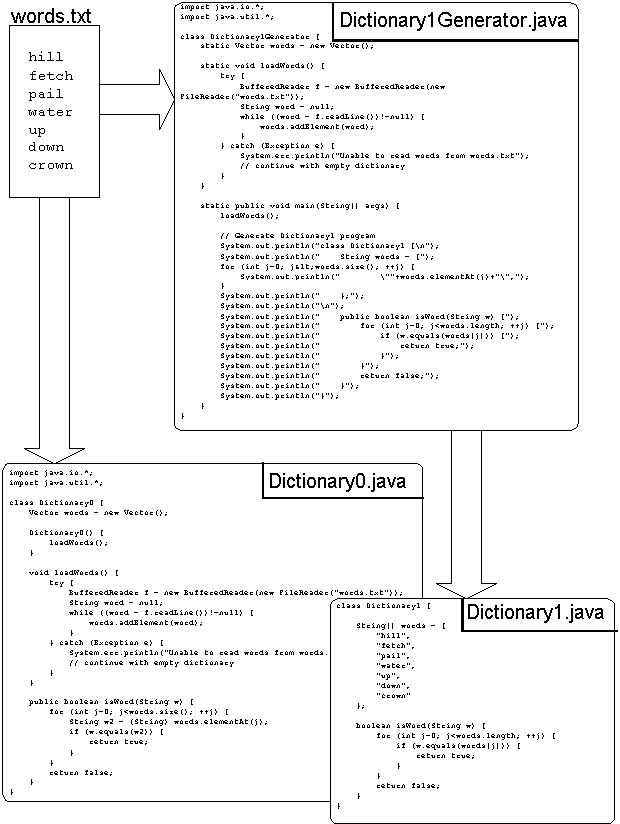
Figure 1-3: Flow diagram with file contents
To fully appreciate the differences between these two approaches, we need the concept of binding time. This is the time at which certain information is determined or bound to a program. Consider the binding time of the dictionary words. In the first case, the words are read at run time. The binding occurs at the time they are read and stored in the Vector. In the second case, they are read in before compile time. This might not seem like a big deal, but it means you must recompile the program if you want to make a change in the words. Program generators introduce a third binding time in addition to the two traditional ones (Figure 1-4).
- Generation time
: The time at which the program is generated after reading a specification of the program (in this case, the specification is simply the list of words).
- Compile time
: The time at which the generated program is compiled.
- Run time
: The time at which the generated program is executed.
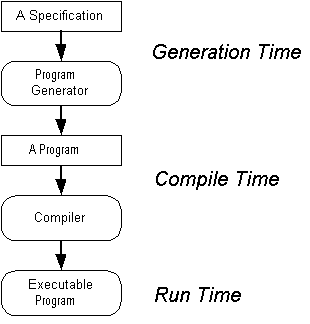
Figure 1-4: Binding times
Jill again ponders the differences among her various programs. As before, she observes the interesting way in which some run-time computation is transferred to other times. In particular, the
loadWords method has been literally moved out of the run time (in Dictionary0) to generation time (in Dictionary1Generator). This is good, because it means the run time is faster and more optimized for the task.
Both Jack and Jill are happy with the results. Jack can continue adding to words.txt. A new Dictionary1.java program can be regenerated whenever they want. Jill is pleased as well, because she really didn't want Jack touching her program. Besides, having two people modifying the same text file at the same time is asking for trouble.
Jill now concentrates on the somewhat slow linear search. She decides it would be easiest to retain the array and do a binary search on a sorted list of words. So she tells Jack to alphabetize the words. After frowning for a few seconds, Jack mumbles agreement. That makes Jill think a little harder. Perhaps it would be better to let the program generator sort the words. In fact, it would be a lot better, because she isn’t sure that words.txt will always be properly sorted. After it has been sorted, how will she know that alphabetical order will be maintained? Just one little slip-up, and her binary search wouldn't work any longer. It would be a lot safer (less error prone) if the program generator sorted the words. Then she would know with more confidence that the words were sorted correctly. Thus, she adds a
sortWords method to sort the words after reading them in and before generating the program.
Later that day, she notices that the word "pail" appears twice in the file words.txt. Although this doesn't alter the behavior of the program, it does make the dictionary larger than it needs to be. Jack starts to explain the systematic way he is typing in words which sometimes unfortunately and accidentally leads to duplicate words. Jill doesn't understand, and she decides it is better to simply add one more tweak to her program generator by detecting and removing duplicate words (which is easily done while sorting).
The program generator now has three distinct parts: getting the data, analyzing/transforming it, and generating the program. And this is also the typical structure of other program generators as well. Figure 1-5 illustrates this structure.
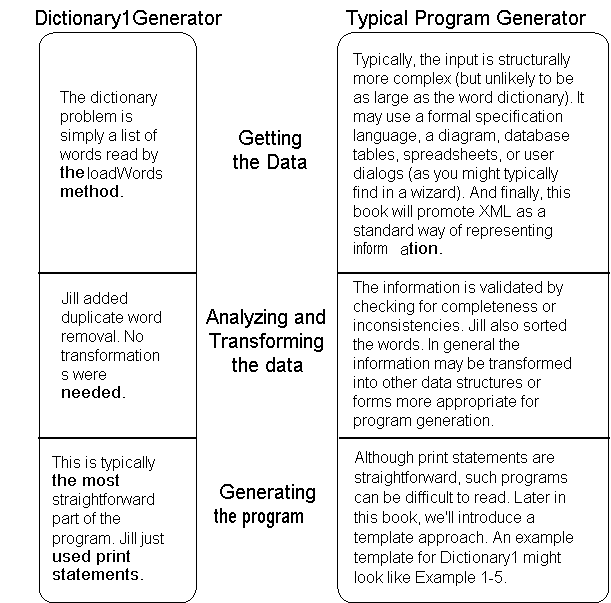
Figure 1-5: Structural comparison between Dictionary1Generator and typical program generators
Example 1-5 shows the outline of the generated program, often called a template. The parts in italics describe how to create the variable parts of the generated program. The remaining ordinary text is simply copied to the output.
Example 1-5: Template for Dictionary1 Generator
class Dictionary1 {
String[] words = {
for each word in words.txt loop
"word",
end-loop
};
boolean isWord(String w) {
for (int j=0; j<words.length; ++j) {
if (w.equals(words[j])) {
return true;
}
}
return false;
}
}
|
1.1 Onward and Upward
Jack and Jill are so comfortable using their program generator that they expand it to solve more and more problems.
- Multiple dictionaries
: They need lots of different dictionaries for variations in the game, including one for English, one for French, one for place names, and others for poets, priests, and politicians. Some games require multiple dictionaries in the same program, so some provision is made for creating and managing multiple dictionary objects.
- Different sets of methods
: As Jack and Jill expand their word-game repertory, they find they need other dictionary methods. For Scrabble they needed only the
isWord method, but for other games they need a way of enumerating the words, and words that partially match words in the list. They add options to the program generator so that only the methods that are needed will be generated. This keeps their class files lean and mean.
Extended dictionaries: As Jack and Jill's business expands, they add more information to the dictionary so that a wider variety of games can be created. For each word, they add antonyms, synonyms, homonyms, rhymes, and all manner of other relations. Their dictionary is no longer just a list of words. And the generated data structures are now becoming a lot more complex than just an array of Strings.
4. Performance differences: Jill discovers that, depending on the context, different data structures and searching algorithms are needed. In some cases memory is critical; in others speed is critical. For speed-critical applications she uses hash tables and doesn't care as much about space. For memory-critical applications (such as downloaded applets on low-bandwidth lines or memory-challenged Java hand-held game machines) she employs Huffman encoding to minimize the space needed to store the dictionary (at the expense of a slower dictionary lookup).
With the addition of these variations, the simple program generator grows and evolves into a large, sophisticated piece of software. These variations should also suggest other issues and complexities that need to be addressed when building real-world program generators.
One of the principal issues is simply understanding the set of variations the program generator should support, and how they may change over time. Chapter 2 describes domain engineering, a systematic process for understanding application domains and building tools for supporting software development in the application domain. Domain engineering entails two steps:
- Domain Analysis
: The first step determines what a domain is, and the variations that must be supported.
- Domain Implementation
: The second step constructs the environment and tools required to support the swift creation of programs within the domain. This step may result in the construction of program generators.
1.2 Other Program Generators
Jack and Jill weren't the first people to conceive of a program generator. Program generators have been used for many years in certain application domains, including, for example:
- Parsers
: A parser reads a sequence of tokens and creates a data structure representing the structure of the information called a parse tree. Creating parsers by hand (writing code manually) is tedious and error prone. Parser generators, such as the classic UNIX utility yacc (bison), read a formal description of the language (expressed in some grammar) along with actions to be taken for each grammar rule, and they output a parser program (Figure 1-6).
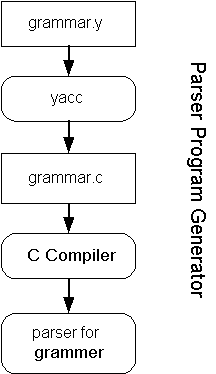
Figure 1-6: Flow diagram for the yacc parser generator
Finite State Machines: Many programs are based on finite state machines. Such programs are best described or documented as a table and/or diagram displaying the various states, events, and state transitions. Given sufficient information about the finite state machine, a program generator can validate and generate a program implementing it. The classic UNIX utility, "lex," is a finite-state-machine program generator and is often used with yacc to parse the tokens of a language.
User Interfaces: Increasingly important components of many programs are user interfaces. They vary from simple buttons (either physical or virtual) to complex graphical interfaces involving many different windows and controls. Writing this code by hand is notoriously difficult, expensive, and error prone. Most such code today is automatically generated from GUI builders and visual programming tools.
Databases: Application generators have a long and productive history in the database area. Given a description of the database tables, relations, business logic, and report templates, a customized database program can be generated (sometimes interpreted).
Web Page Generation: Java Server Pages (JSP) are a means for creating dynamic content on the Web. A Java Server Page is a template of a Web page with interspersed Java code that creates the page’s variable parts.
There are many other specialized areas where gains in efficiency and productivity are possible, but there are no commercially available systems for a variety of reasons, including a smaller niche market or an immature domain that lacks standardized approaches.
If you can't buy the tools you need, then you'll have to build your own, just like Jack and Jill. And isn't this why you're reading this book? This book will show you how to plan, design, and build program generators in a systematic manner. You will also be able to evaluate different approaches and take various shortcuts to reduce the amount of work needed for building such tools.
1.3 Why Use Program Generators?
Let’s review the motivations for using (and creating) program generators. In general, the number one reason is increased productivity. Some of the reasons below are evident in the simple dictionary example, but others won't become evident until we look at more complex examples.
- Specification Level versus Code Level
: The file words.txt represents what is usually called the specification. The specification expresses the what. In the dictionary example, the what is simply the list of words. In the more general case, the what expresses what application software to generate. The words.txt file (representing the specification) and the Dictionary1Generator.java code will be easier to maintain than Dictionary1.java. In general, specifications are much easier to read, write, edit, debug, and understand than the code that implements the specification. For example, the implementation code may contain detailed knowledge about programming techniques, algorithms, or data representation that we don’t need in order to understand the specification. For example, if the dictionary program used hash table techniques to implement the word list, the specification would still contain only words and have no references to hash tables. The difference between the specification and generated code will largely determine the increased productivity obtained by using program generators.
- Separation of Concerns
: All too often software is constructed with different concerns all jumbled together. This makes it difficult for different people to sort out and work on the part that they are responsible for without interfering with other people's parts. Jack is responsible for the word list, and Jill is responsible for the data representation and algorithms. Jack and Jill were able to separate their respective responsibilities into two separate files and work independently of each other. In typical software projects, different responsibilities are mixed together in very confusing ways, making it difficult for more than one person to work on a task simultaneously and independently. Domain engineering and program generators provide a way for separating concerns.
- Multiple Products
: In the dictionary problem, only Dictionary1.java was generated. There isn't much else to generate for the dictionary problem, but in more complex but typical situations many other files may also be generated, including, for example:
- documentation about the software
- user documentation
- test scripts
- other software tools related to the specification
- diagrams or pictures
- simulation tools
- Multiple Variants
: The dictionary solution can handle any number of dictionaries, each producing a specific variant of the original program. Program generators provide an effective way of handling multiple variants of a program. The collection of variants is called a program family. Program generators represent program families, not just single system-specific programs.
- Consistency of Information
: One of the most difficult and expensive software maintenance issues is the consistent-update problem. All too often, fixing a bug or updating software introduces other errors, because a "piece" of information was not updated consistently across the whole product. In a software-generation approach, one simply updates the specification and regenerates the software.
- Correctness of Generated Products
: Many program generators create thousands of lines of code that are far more reliable than if they were hand crafted. Imagine solving the dictionary problem by handing the words.txt file to some coders and asking them to write out by hand the Dictionary1.java file. What confidence would you have that it was done correctly? How would you make sure it was done correctly? If changes were made to words.txt, how confident would you be that the same changes were made to Dictionary1.java? How would you confirm that words.txt and Dictionary1.java were consistent after some changes were made? Imagine the increased difficulties if we also asked Jack to sort the list. Most program generators are far more complex than the dictionary problem, and the correctness issue becomes more critical. Verifying the correctness of a program generator is more difficult than just verifying the correctness of a generated program.
- Improved Performance of Customized Software
: In some cases, program generators can construct optimized code. If there is sufficient information to analyze how the program will be used, this can be used to create very specific customizations for optimal performance. There are many trade-offs between time, space, and other resources. Depending on the context, one resource may be more important than others, and program generators can use this information to create very specific optimized programs. For example, Jill chose between hash tables and Huffman encoding to optimize speed or memory use.
1.4 Organization of the Book
Jack and Jill stumbled into program generators and learned by painful experience. You can skip some of those painful experiences, and you can skip around the various chapters of this book (Figure 1-7). Chapters 2, 3, and 4 provide glimpses into Domain Engineering concepts that provide the systematic development framework for program generators. Chapter 5 is an introduction to XML. Chapters 6 and 7 show alternative techniques to program generation. Chapters 8 through 12 focus on program generators, Chapter 8 showing "what to generate" and Chapters 9 to 12 "how to generate." Finally, Chapter 13 is devoted to the relationship between program generators and component-oriented programming.
The story of Jack and Jill continues in Chapter 3. A more substantial example is created called the Play domain. The Play domain language in XML is created in Chapter 5 and then extensively used in Chapters 6 through 12. Visit
http://craigc.com for copies of the examples or the latest information about program generators.
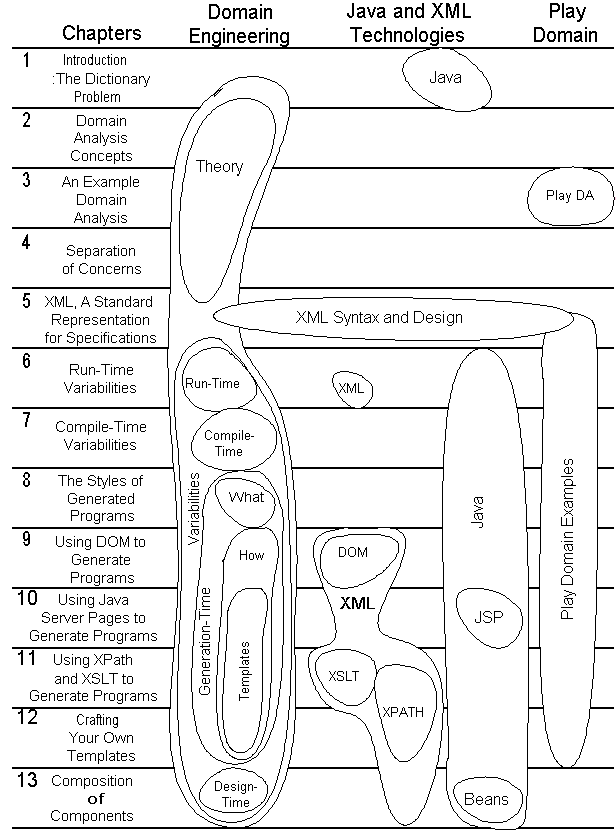
Figure 1-7: Book Organization